Grouping data
Grouping data enables us to create an overview of some relevant dimensions of the underlying data, while leaving the rest out: think of it as creating a summary of the data we’re currently interested in analyzing.
For that purpose, SQL provides a default set of aggregation functions. For example, this is how we can get the sum of all invoice total amounts:
SELECT sum(total) FROM learnsql.invoices;
In a similar way, we could get the maximum invoiced amount:
SELECT max(total) FROM learnsql.invoices;
We're not limited to running a single aggregation per query, by the way!
SELECT
count(*), -- count all rows
avg(total), -- get the average invoiced amount
min(total), -- get the minimum invoiced amount
max(total), -- get the maximum invoiced amount
sum(total) -- get the total invoiced amount
FROM learnsql.invoices;
Describing a whole table with a single value is not always good enough for analysis, which is why SQL also provides a way to control the granularity of our results by creating groups of data on which aggregations will happen. As an example, this is how we can get the sum of the amounts invoiced in each country:
SELECT country, sum(total)
FROM learnsql.invoices
GROUP BY country;
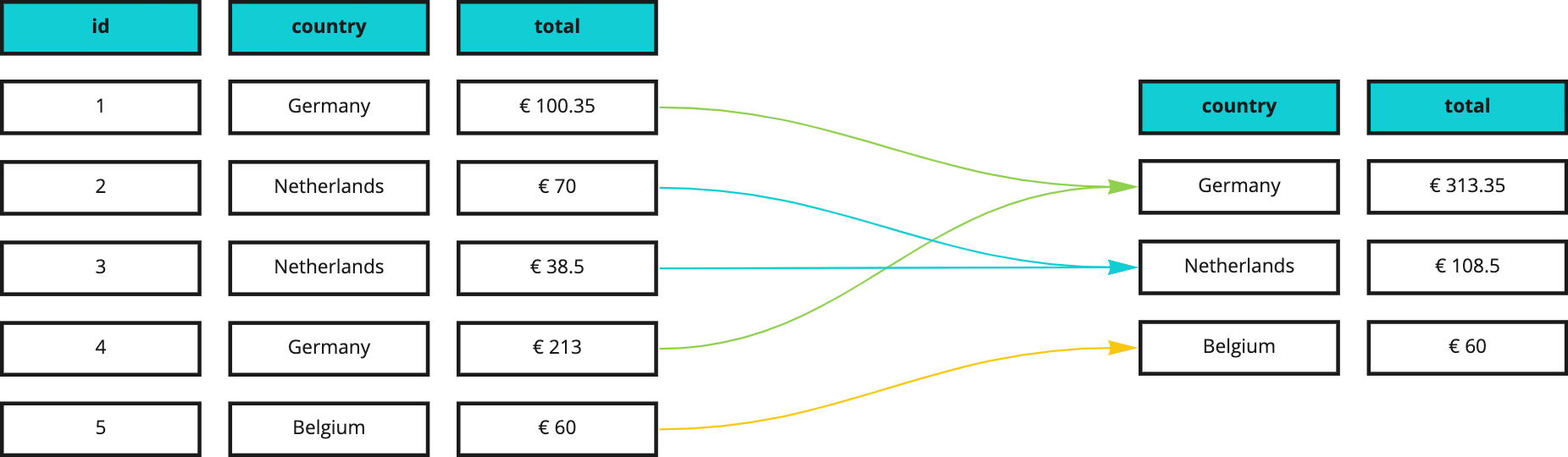
New syntax: GROUP BY <column1, …, columnN> clause
Having clause
Let’s make the previous example a bit more complex, by saying that we would like to group invoices by country, but only for those countries in which there has been more than one invoice. We cannot address this request with a regular WHERE clause, because we’ve been asked to filter on an aggregated value (the count of invoices in each country), so we need to use the HAVING clause:
SELECT country, sum(total)
FROM learnsq.invoices
GROUP BY country
HAVING count(*) > 1;
The HAVING clause expects an aggregation function and a condition to test: according to our needs, we could use sum(...), avg(...), or any other aggregation function.
Grouping by multiple columns
We’re not limited to grouping by a single column: we can create subgroups to further refine our analysis. Let’s say, for example, that we want to group by country and then, within each group, by the invoices’ payment status (`paid` column):
SELECT country, paid, sum(total)
FROM learnsql.invoices
GROUP BY country, paid;
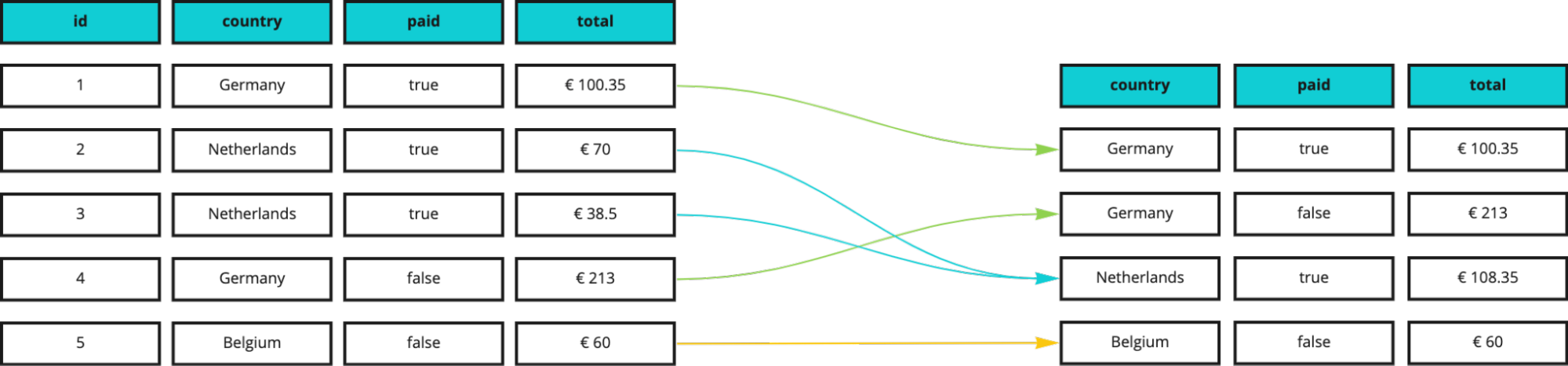
As you can see, we now have 4 groups instead of 3, because the original dataset contains 2 invoices in Germany, only one of which has already been paid.
Important: when using multiple group columns, they must appear in the same order both in the `SELECT` clause and in the `GROUP BY` clause; if not, the DBMS will return an error.
References: Analyzing data with aggregate functions
Practice
Are you ready to practice what you’ve just learned? Head over to the Notebook and try to solve the exercises you find there!
Note: the solution to each exercise is in the collapsed block right below it: you can expand it by clicking the arrow icon that appears on the far left when you hover it.